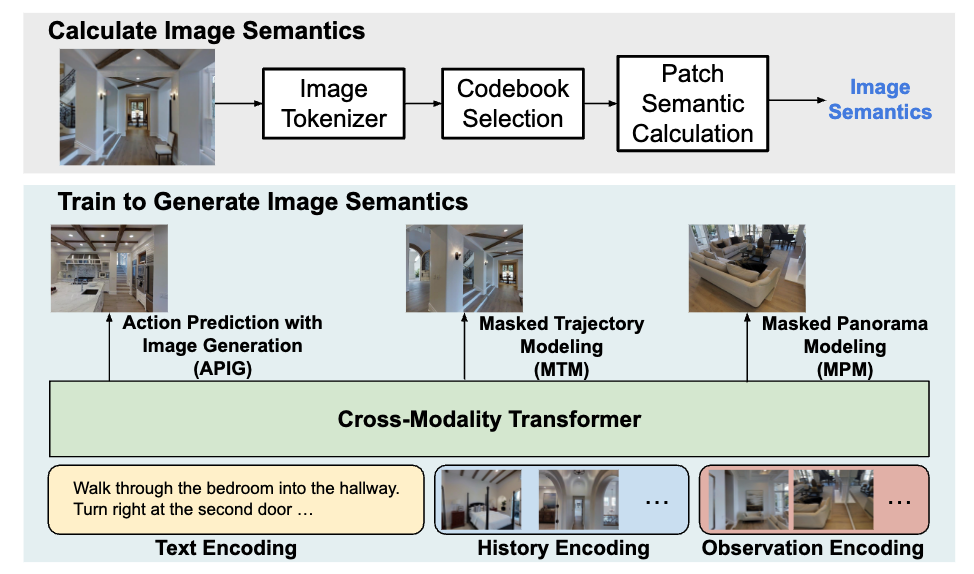
Vision-and-Language Navigation (VLN) is the task that requires an agent to navigate through the environment based on natural language instructions.
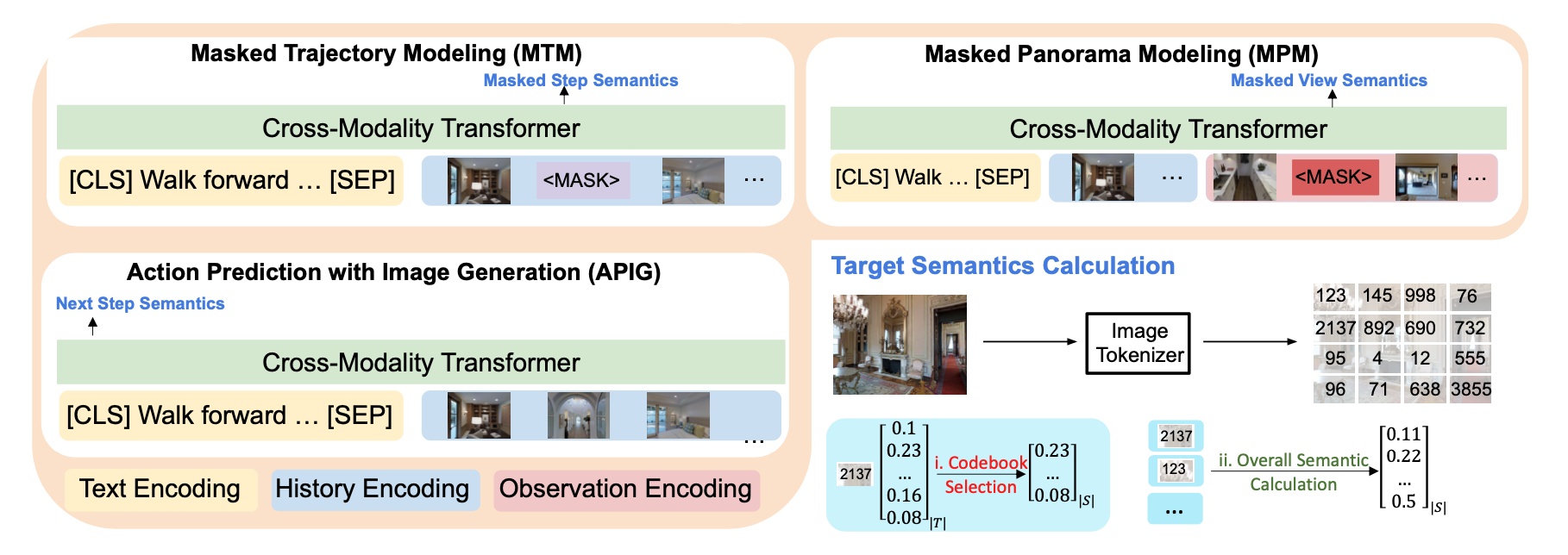
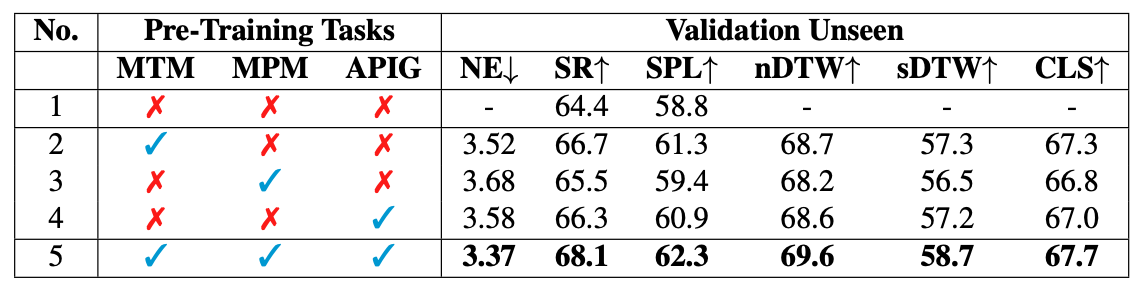
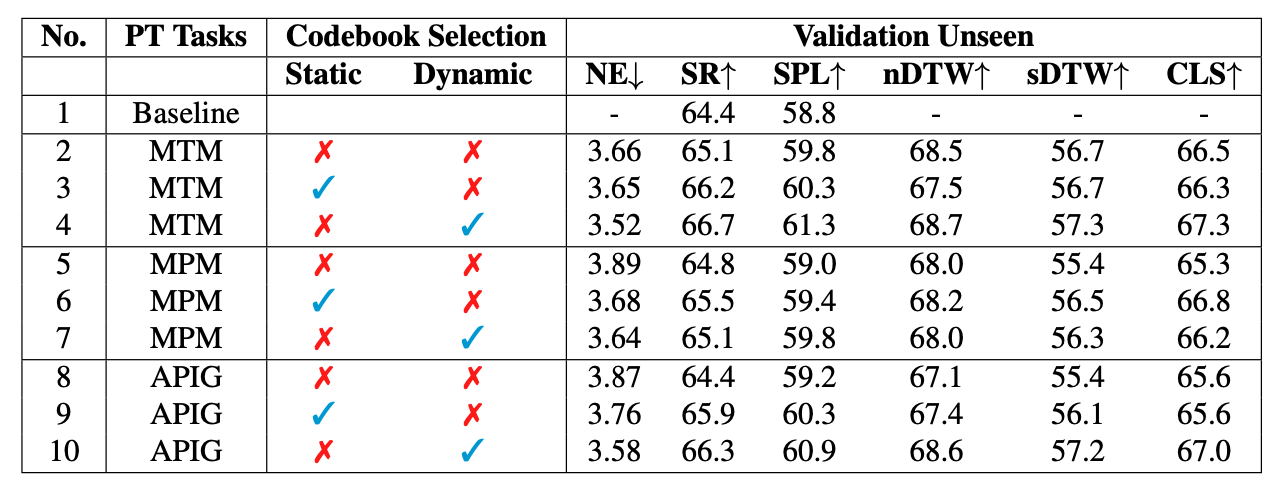
At each step, the agent takes the next action by selecting from a set of navigable locations. In this paper, we aim to take one step further and explore whether the agent can benefit from generating the potential future view during navigation. Intuitively, humans will have an expectation of how the future environment will look like, based on the natural language instructions and surrounding views, which will aid correct navigation. Hence, to equip the agent with this ability to generate the semantics of future navigation views, we first propose three proxy tasks during the agent's in-domain pre-training: Masked Panorama Modeling (MPM), Masked Trajectory Modeling (MTM), and Action Prediction with Image Generation (APIG). These three objectives teach the model to predict missing views in a panorama (MPM), predict missing steps in the full trajectory (MTM), and generate the next view based on the full instruction and navigation history (APIG), respectively.
We then fine-tune the agent on the VLN task with an auxiliary loss that minimizes the difference between the view semantics generated by the agent and the ground truth view semantics of the next step. Empirically, our VLN-SIG achieves the new state-of-the-art on both Room-to-Room dataset and CVDN dataset. We further show that our agent learns to fill in missing patches in future views qualitatively, which brings more interpretability over agents' predicted actions. Lastly, we demonstrate that learning to predict future view semantics also enables the agent to have better performance on longer paths.